golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
go语言爬虫框架:
gocolly/colly,goquery,colly,chromedp,webloop,go_spider,Pholcus Pholcus 幽灵蛛重量级爬虫软件(含3种操作界面) - Golang中国henrylee2cn/pholcus_lib: 公共维护的Pholcus爬虫规则库
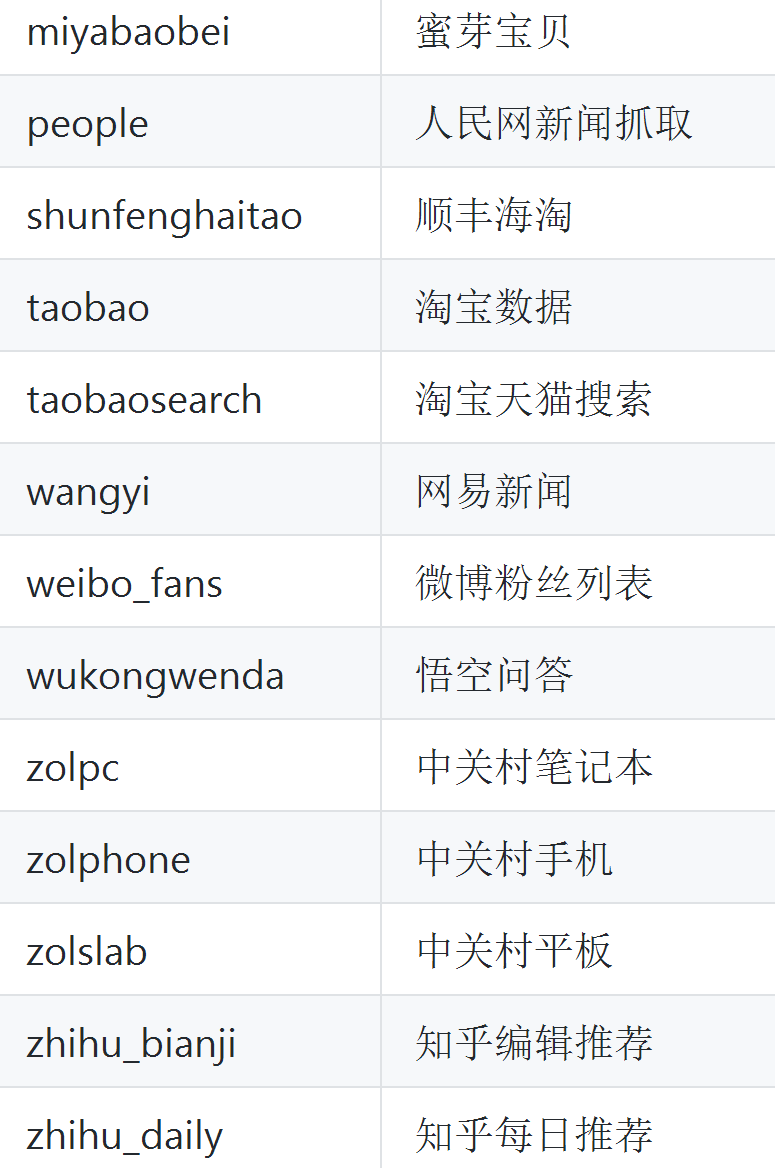
用python的scrapy,所有平台都能跑,scrapy是主流方案,各种周边都很成熟,爬视频python有现成的包
python的pyspider框架比较完善,抓取大量网站,解析大量页面时做分布式和后台管理都比较方便
java爬虫配合jsoup也是不错的选择
nodejs主要框架有cheerio、crawler、spiderman:
用nodejs爬指定的少量网站,用request加cheerio就足够了
cheerio | Fast, flexible, and lean implementation of core jQuery designed specifically for the server.crawler - npmltebean/spiderman: a crawler with visualized config board